








Validated against 50K+ human-graded responses
QWK scores: Automated grading system efficacy
Demo Types
Use Cases
Feedback Aide is a white-label, API-based automated grading system that adds fast, accurate essay grading and personalized learner feedback to your product. Built for seamless integration, it’s continuously validated against expert human graders to deliver reliable scoring from day one and stronger performance with every release.
How we test Feedback Aide
To validate Feedback Aide’s performance, we evaluated it against a bank of 50,000+ essays that had already been scored by professional human graders. These came from both public and partner datasets and covered grade levels from 3 through university.
Each response was scored using real-world rubrics (analytic and holistic) across tasks like narrative writing, persuasive arguments, literary analysis, and research assignments. As Feedback Aide had no prior exposure to these responses, this was a pure zero-shot evaluation.
We benchmarked Feedback Aide’s output using Quadratic Weighted Kappa (QWK), an industry-standard measure of agreement between scores.
A quick guide to QWK scores
QWK measures how closely two graders—whether human or AI—agree on scores. It adjusts for chance and penalizes bigger errors more than smaller ones.
For example, imagine you're hired to grade college entrance essays. Your scores are compared to expert human graders. If your QWK falls between 0.4–0.6, you likely need more training. Above 0.8? You're scoring like a pro.
Why do QWK scores matter? Because they directly reflect how fair and reliable the grading is for learners.
TL;DR: The higher the QWK score, the closer the alignment.

How Feedback Aide compares to expert human graders
Overall accuracy
In a dataset of 850 essays scored across eight traits, Feedback Aide achieved a:
- QWK of 0.93
- Kappa of 0.74 (strong agreement, even after adjusting for chance)
- Correlation Coefficient of 0.93 (scoring patterns that move almost identically with human judgment)

This scatter graph visualizes the strong alignment between human-assigned scores (x-axis) and those from the Feedback Aide (y-axis) across a dataset of 850 essays. Each essay was evaluated on eight different rubric traits, contributing to a total of 32 marks.
Trait-level performance
Each essay was scored across eight distinct traits, such as ideas, structure, and spelling. In this study, traits like “ideas and elaboration” achieved QWK scores above 0.80, aligning closely with expert raters. Traits like “spelling” scored lower, helping us identify areas for targeted refinement.
Growth over time
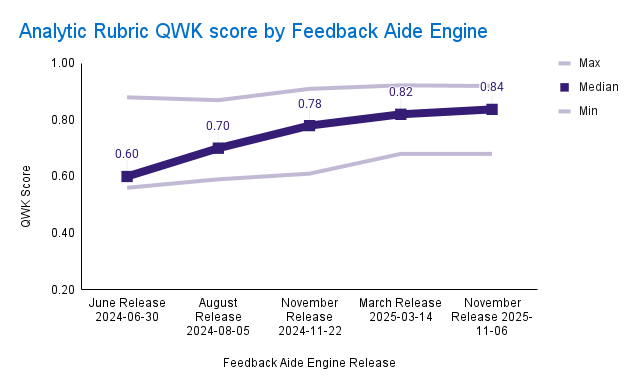
We measure Feedback Aide's progress using two metrics critical to reliable, scalable grading: accuracy and consistency.
- Accuracy tells us how closely Feedback Aide matches expert human scores.
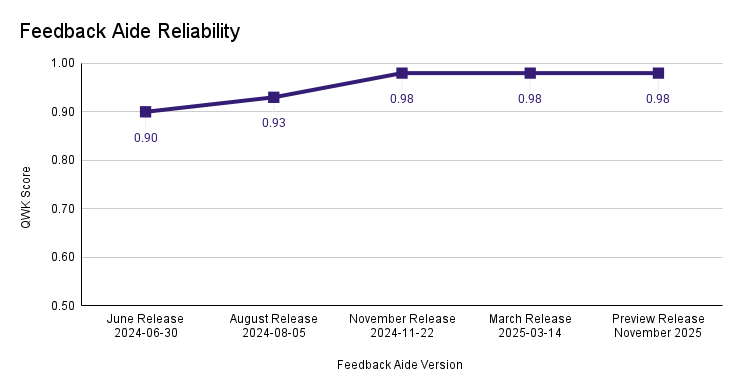
- Consistency shows how reliably it scores the same response when tested repeatedly.
Across both these metrics, Feedback Aide’s performance has improved with each new release.
Accuracy improvements

Expert-level consistency

What this means
Feedback Aide delivers high-quality scoring right out of the box. With no training required, it achieves human-level accuracy, strong trait-level alignment, and best-in-class scoring consistency. As a white-label API, Feedback Aide fits effortlessly into your product—and gets better with every release.
Put Feedback Aide to the test
Looking to validate AI-powered scoring before integrating it into your platform? We’ll run Feedback Aide on your content and show you exactly how it performs.
Get in touch at team@learnosity.com to see Feedback Aide in action.